各位前輩好:
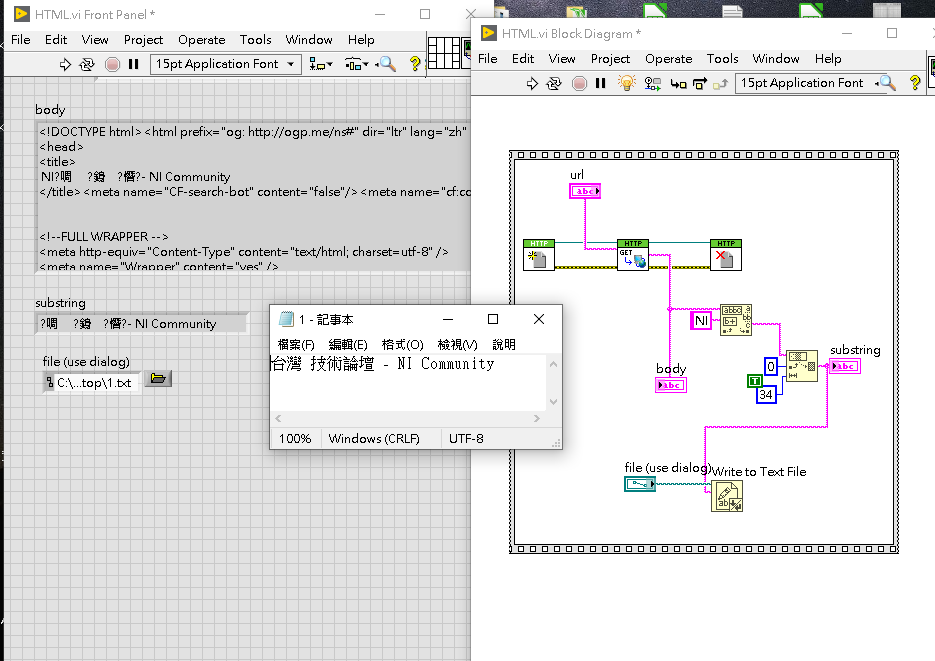
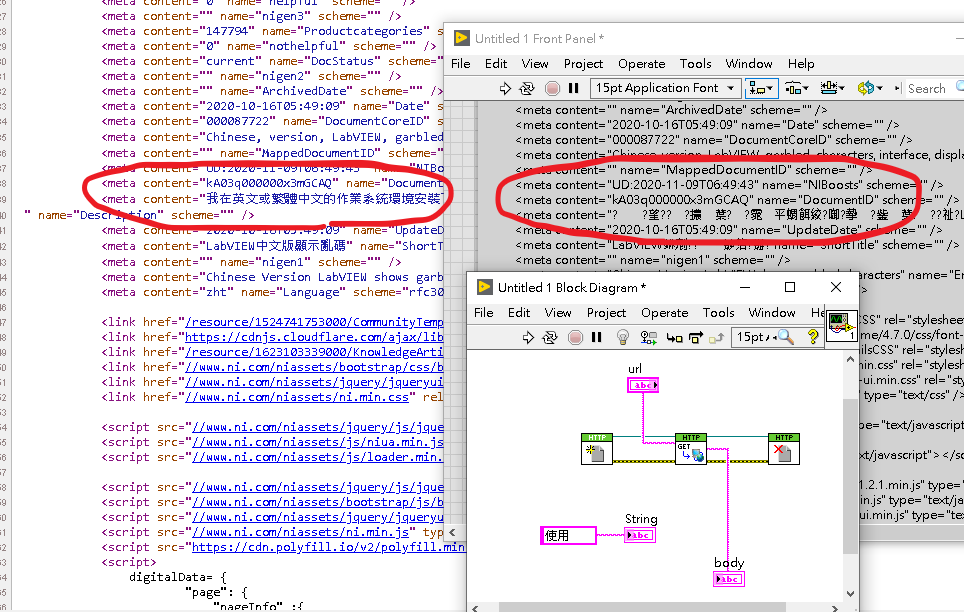
如將HTML檔讀出後,中文的部分為何會於字串中出現亂碼?該怎麼於顯示面板中正常顯示??
但,如嘗試將所讀出的字串,再存入至TXT檔中,這就會正常顯示於記事本
因為你從網頁上讀下來的中文是unicode編碼,labview預設顯示是不支援的
但有下面兩種方式可以用:
1.找到labview.exe執行檔的資料夾,打開LabVIEW.ini,新增UseUnicode=TRUE後存檔,再重新開啟Labview。
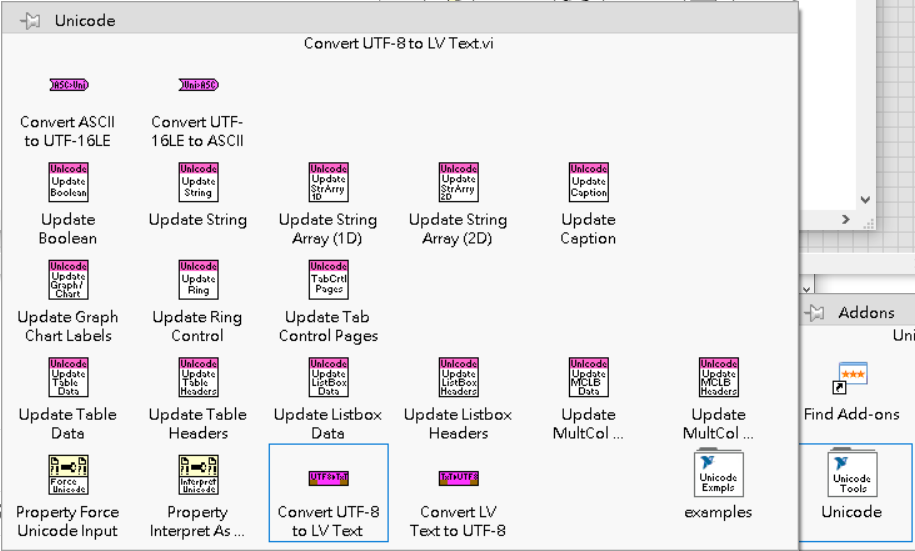
2.安裝unicode tool,然後使用UTF-8 to LV Text,也可以把unicode的中文轉成labview可以顯示的編碼。
您好,經測試結果,於Labview.ini檔中插入UseUnicode=TRUE仍無法轉換…
但是使用unicode tool這方式,經測試是可以的!!!
以上是測試的結果…謝謝
其實使用Python來擷取網頁就完全沒有這些問題喔。你可以使用Python擷取網頁後,再把你要的資訊傳回LabVIEW。單純把LabVIEW當成前端。後端城市邏輯就交給Python就可以了。