以下資料轉載自:https://developer.nvidia.com/blog/optimizing-and-improving-spark-3-0-performance-with-gpus/
Apache Spark繼續致力於分析Apache Hadoop於15年前開始的大數據,現已成為大規模分佈式數據處理的領先框架。如今,成千上萬的數據工程師和科學家正在與超過16,000多家企業和組織合作。
Spark之所以從Hadoop奪走火炬,原因之一是因為它平均可以將數據處理速度提高約100倍。這些功能是由250多家公司的1000多名貢獻者在開放社區中創建的。Databricks的創始人開始了這項工作,僅他們的平台每天就旋轉超過一百萬個虛擬機來分析數據。
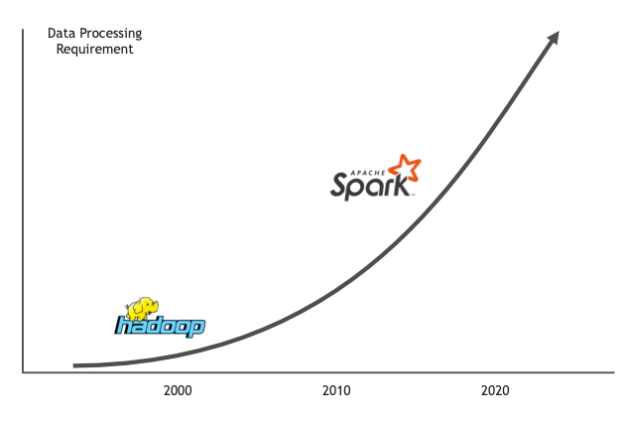
圖1. Spark一直致力於分析Hadoop在15年前開始的大數據,現在它已成為分佈式,橫向擴展數據分析的領先框架。
借助用於SQL,流處理,機器學習(ML)和圖處理的高級運算符和庫,Spark使使用交互式shell,筆記本或打包的Scala,Python,R或SQL輕鬆構建並行應用程序。應用程序。Spark使用功能性編程模型和關聯的查詢引擎Catalyst支持批處理和交互式分析。Spark將作業轉換為查詢計劃,並跨集群中的節點計劃查詢計劃內的操作。
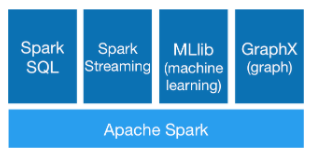
圖2. Apache Spark組件。
在每個版本的Spark中,都進行了改進,使其更易於編程和執行。Apache Spark 3.0通過改進Spark SQL性能和NVIDIA GPU加速的創新延續了這一趨勢,這些我將在本文中介紹。
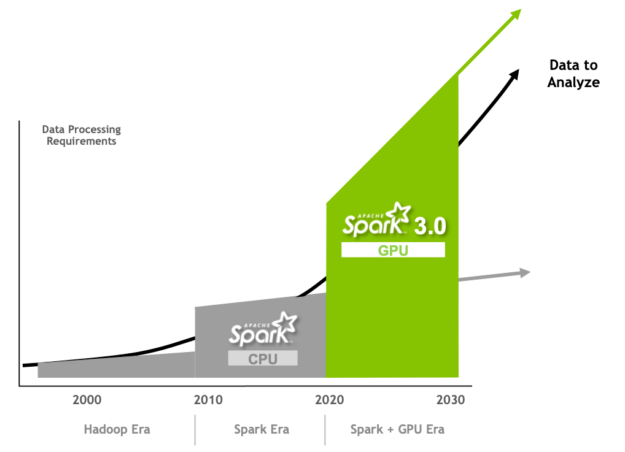
圖3.使用GPU創新和加速Spark 3.0性能,以滿足並超越數據處理的現代要求。
適用於Spark SQL的Spark 3.0優化
使用其SQL查詢執行引擎,Apache Spark可實現批處理和流數據的高性能。該引擎以大規模並行處理(MPP)技術的思想為基礎,並由最先進的DAG調度程序,查詢優化器和物理執行引擎組成。大多數Spark應用程序操作都是通過查詢執行引擎運行的,因此Apache Spark社區已投資進一步提高其性能。根據TPC-DS基準測試,自適應查詢執行,動態分區修剪和其他優化使Spark 3.0的執行速度比Spark 2.4快約2倍。
Spark 3.0自適應查詢執行
Spark 2.2在現有的基於規則的查詢優化器中添加了基於成本的優化。Spark 3.0現在具有運行時自適應查詢執行(AQE)。通過AQE,將從查詢計劃的完成階段中檢索到的運行時統計信息用於重新優化其餘查詢階段的執行計劃。使用AQE時,Databricks基準測試的速度提高了1.1倍至8倍。
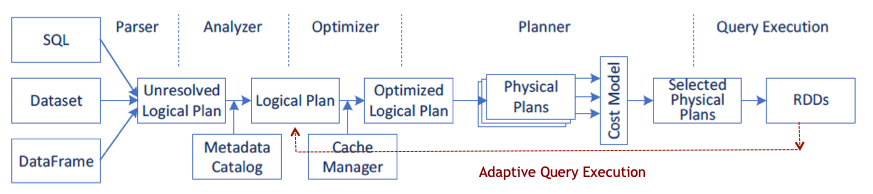
圖4.通過AQE,從查詢計劃的完成階段檢索到的運行時統計信息將用於重新優化查詢計劃。
Spark 3.0 AQE優化功能包括以下內容:
- 動態合併洗牌分區: AQE可以通過查看洗牌文件統計信息,在洗牌階段將相鄰的小分區合併為更大的分區,從而減少查詢聚合的任務數量。
- 動態切換 聯接策略: AQE可以根據聯接關係大小在運行時優化聯接策略。例如,將排序合併聯接轉換為廣播哈希聯接,如果聯接的一側足夠小以適合內存,則將其執行得更好。
- 動態優化偏斜連接: AQE可以使用運行時統計信息以排序合併連接分區大小檢測數據偏斜,並將偏斜分區拆分為較小的子分區。
Spark 3.0動態分區修剪
Spark 2.x靜態分區修剪通過允許Spark僅讀取目錄和文件的子集來進行與分區過濾條件匹配的查詢,從而提高了性能。Spark 3.0在運行時為類似於數據倉庫查詢的查詢引入了這種數據修剪技術,該查詢將分區事實表與維表中的已過濾值結合在一起。減少讀取和處理的數據量可節省大量時間。
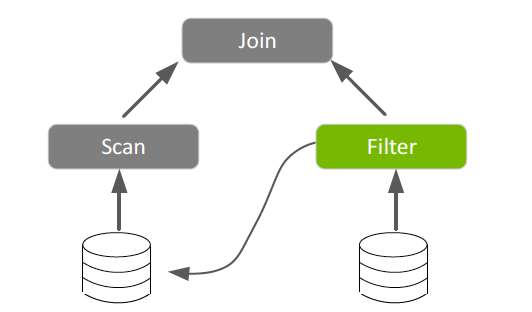
圖5.用於在運行時修剪分區的過濾值 。
Spark 3.0 GPU加速
GPU因其每翻牌價格(性能)極低而受歡迎。他們正在通過加快多核服務器的並行處理速度來解決當今的計算性能瓶頸。
一個CPU由幾個內核組成,這些內核針對順序串行處理進行了優化。GPU具有大規模並行架構,該架構包含數千個更小,更高效的內核,旨在同時處理多個任務。與僅包含CPU的配置相比,GPU能夠更快地處理數據。在過去的幾年中,GPU一直負責DL和ML模型訓練的發展。但是,數據科學家的時間中有80%花費在數據預處理上。
儘管Spark以分區的形式在節點之間分配計算,但分區內的計算歷來是在CPU內核上執行的。Spark通過添加內存數據處理減輕了Hadoop中的I / O問題,但是現在瓶頸已經從I / O轉移到了越來越多的應用程序的計算上。GPU加速計算的出現可以避免這種性能瓶頸。
為了滿足並超越現代數據處理的要求,NVIDIA與Apache Spark社區合作,通過發布Spark 3.0和開源的Spark RAPIDS Accelerator將GPU納入Spark的本機處理。有關更多信息,請參閱Google Cloud和NVIDIA的增強合作夥伴關係可加速計算工作負載。
Spark中GPU加速的好處很多:
- 數據處理,查詢和模型訓練的完成速度更快,從而縮短了獲得結果的時間。
- 相同的GPU加速基礎架構可用於Spark和ML / DL框架,從而無需單獨的集群,並為整個管道提供GPU加速訪問。
- 需要更少的服務器,從而降低了基礎架構成本。
適用於Apache Spark的RAPIDS加速器
RAPIDS是一套開源軟件庫和API,用於完全在GPU上執行端到端數據科學和分析管道,從而可以顯著提高速度,特別是在大型數據集上。建立在頂部NVIDIA CUDA和UCX的,RAPIDS加速器的Apache星火使GPU加速的SQL和數據幀的操作和星火洗牌,沒有代碼的變化。
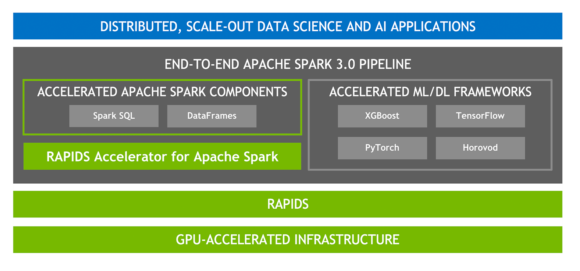
圖6. Apache Spark加速的端到端AI平台堆棧。
加速的SQL / DataFrame
Spark 3.0支持SQL優化器插件,以使用列式批處理而非行處理數據。列數據對GPU友好,RAPIDS加速器插入此功能即可加速SQL和DataFrame運算符。借助RAPIDS加速器,對Catalyst查詢優化器進行了修改,以識別可通過RAPIDS API加速的查詢計劃中的運算符(主要是一對一映射),並在執行時在Spark集群中的GPU上調度這些運算符查詢計劃。
加速洗牌
當根據階段之間的現有數據幀創建新的DataFrame時,按值對數據進行排序,分組或聯接的Spark操作必須在分區之間移動數據。該過程稱為隨機(shuffle),涉及磁盤I / O,數據序列化和網絡I / O。新的RAPIDS加速器改組實現利用UCX來優化GPU數據傳輸,從而在GPU上保留盡可能多的數據。它利用最佳的可用硬件資源找到了在節點之間移動數據的最快路徑,包括繞過CPU進行節點間和節點間的GPU到GPU內存的傳輸。
加速器感知調度
作為主要Spark計劃的一部分,該計劃旨在更好地統一Spark上的DL和數據處理,GPU現在已成為Apache Spark 3.0中的可調度資源。這使Spark可以調度具有指定數量的GPU的執行程序,並且您可以指定每個任務需要多少個GPU。Spark將這些資源請求傳達給基礎的集群管理器:Kubernetes,YARN或Standalone。您還可以配置發現腳本,該腳本可以檢測由集群管理器分配的GPU。這極大地簡化了需要GPU的ML應用程序的運行,因為以前您必須解決Spark應用程序中缺少GPU調度的問題。
加速的XGBoost
XGBoost是可擴展的,分佈式的,梯度增強的決策樹(GBDT)ML庫。
XGBoost提供並行樹增強功能,並且是用於回歸,分類和排名問題的領先的ML庫。RAPIDS團隊與分佈式機器學習通用(DMLC)XGBoost組織密切合作,並且XGBoost現在包括無縫的嵌入式GPU加速。
現在,Spark 3.0 XGBoost還與Rapids加速器集成在一起,可通過以下功能提高性能,準確性和成本:
- GPU加速Spark SQL / DataFrame操作
- XGBoost訓練時間的GPU加速
- 內存中優化存儲的功能可有效利用GPU內存
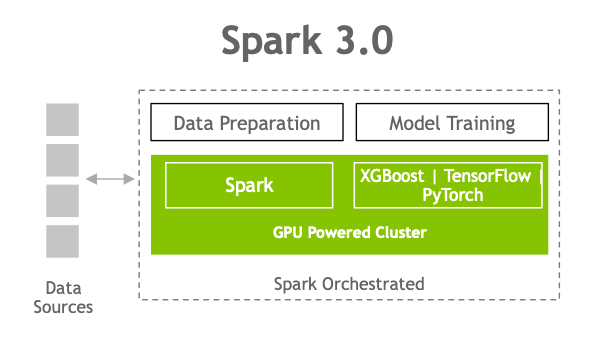
圖7.在Spark 3.0中,您現在可以有一個管道,從數據提取到數據準備,再到在GPU驅動的集群上進行模型訓練 。