Apache HBase + Apache Phoenix 等同「關聯式資料庫(MSSQL, MySQL等)」
- OLTP(線上交易處理):Online transaction processing,如進銷存系統,使用Apache HBase + Apache Phoenix搭配使用來實作
- OLAP(線上分析處理):Online analytical processing,使用Apache Hive來實作
參考資料:https://www.marketersgo.com/market/202007/bigdata-大數據/
舉例,建築物監測數據,一次4KB,每天記錄兩次,一年須要42365=2.85MB,10年需要28.515MB。監測1000個建築物10年,需要27.85GB。這種資料使用傳統IT技術(MSSQL, MySQL)就可以解決,不須使用Hadoop。
根據「數據行銷」時代來臨:什麼是大數據?4V是什麼?如何應用大數據?,以及IBM大數據圖表「在台灣,大數據特指數據量極其巨大的數據集,通常是指一天內可生成1TB以上的數據量」。
RAW data是指沒有修改的資料,經過修改過就是資訊,而不是資料。
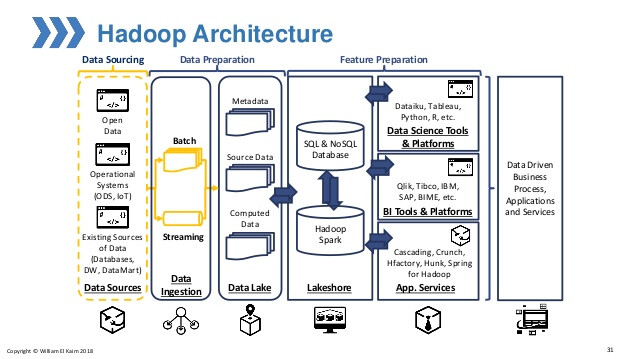
Hadoop架構
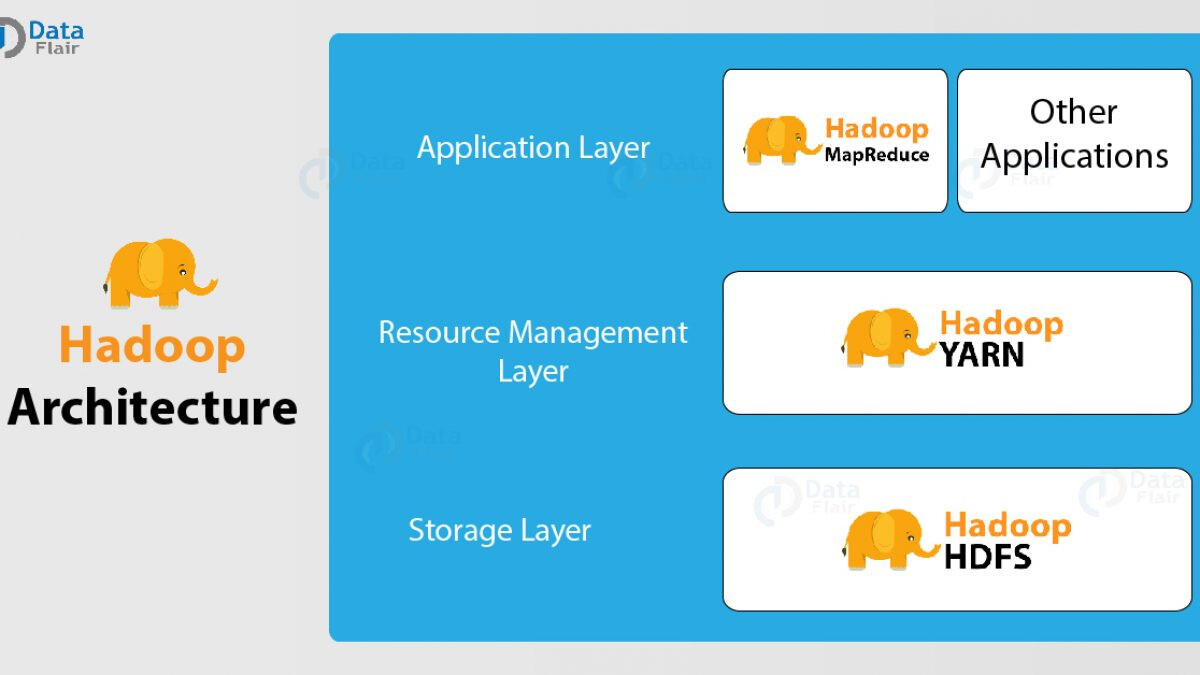
上圖的 Other Applications 最通常就是使用Spark。下圖是Spark資料流:

Map Reduce是資料處理引擎,其功能類似於MSSQL。
Hadoop架設為4台電腦起跳,而非單台電腦。
Hadoop官網:https://hadoop.apache.org/
Hadoop專案的架構包含:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
- Hadoop Ozone: An object store for Hadoop.
Hadoop被戲稱為disk killer;Spark被戲稱為memory killer。
Hadoop的相關搭配專案:
- Ambari™: A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster health such as heatmaps and ability to view MapReduce, Pig and Hive applications visually alongwith features to diagnose their performance characteristics in a user-friendly manner.
- Avro™: A data serialization system.
- Cassandra™: A scalable multi-master database with no single points of failure.
- Chukwa™: A data collection system for managing large distributed systems.
- HBase™: A scalable, distributed database that supports structured data storage for large tables.
- Hive™: A data warehouse infrastructure that provides data summarization and ad hoc querying.
- Mahout™: A Scalable machine learning and data mining library.
- Pig™: A high-level data-flow language and execution framework for parallel computation.
- Spark™: A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation.
- Submarine: A unified AI platform which allows engineers and data scientists to run Machine Learning and Deep Learning workload in distributed cluster.
- Tez™: A generalized data-flow programming framework, built on Hadoop YARN, which provides a powerful and flexible engine to execute an arbitrary DAG of tasks to process data for both batch and interactive use-cases. Tez is being adopted by Hive™, Pig™ and other frameworks in the Hadoop ecosystem, and also by other commercial software (e.g. ETL tools), to replace Hadoop™ MapReduce as the underlying execution engine.
- ZooKeeper™: A high-performance coordination service for distributed applications.
Hadoop叢集架構: