我有兩張GPU卡,分別是:
- GTS450,微星 N450GTS-MD1GD3 顯示卡
- GTX580,技嘉 N580D5-15I-B 1536M DDR5/DVI2+miniHDMI1/384-bit
GTS450
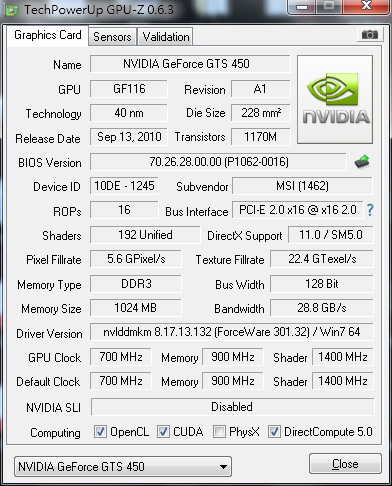
GTX580
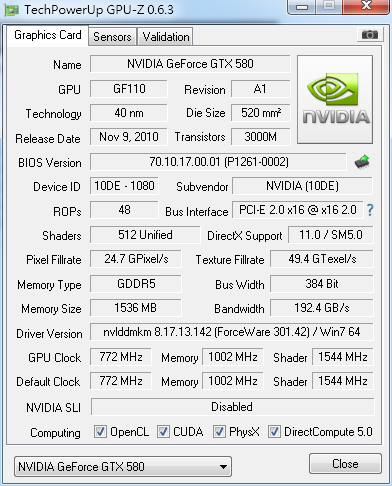
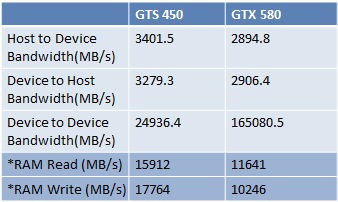
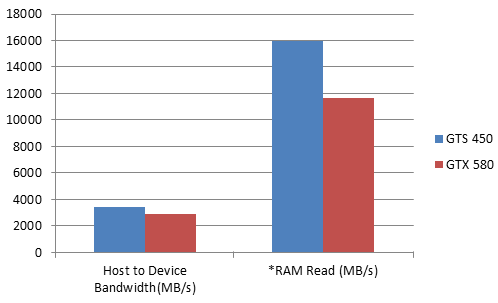
從上面兩張圖片可以看到,GTS450的bandwidth是28.8GB/s,GTX580的bandwidth是192.4GB/s。從這個數據看來,GTX580大勝GTS450,但是,如果執行nvidia cuda sdk裡面的bandwidthTest.exe,跑出來的結果如下圖所示:
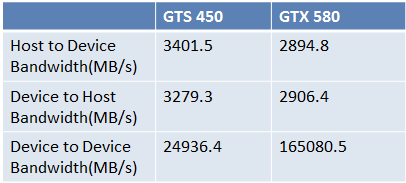
看起來變成GTS450比GTX580好很多,為什麼為這樣呢?